



If your site is linked to from one or more that form part of a trusted set of seed sites within your topic, or one that’s only a short distance (number of links) away, these links are likely more valuable.
Seed sites are a collection of high-quality web pages that Google deems to be reliable, diverse in topic and well-connected (linking) to other web pages. The distance between seed sites and a webpage within a set of pages to be ranked is used to determine a ranking score (link distance ranking).
In other words, seed sites are a collection of authoritative and spam-free sites, and earning links from these (and sites they directly link to) is valuable. Sites that sit a shorter distance from these are trusted more by Google.
The New York Times is one example that Google has given, alongside the now-defunct Google directory.
We don’t know what the other seed sites are, but by the information provided in Google’s “Producing a ranking for pages using distances in a web-link graph” patent, we can at least make a well-informed assumption on the type of sites that these could be.
We also know that the seed set is broken up by topic.
This is largely about identifying spam sites or determining those that aren’t and are therefore trusted. And we all want to be earning links that are trusted, right?
This may also give insight into how Google ignores links deemed to be spam.
If you work in digital PR or are responsible for earning links, then you need to know what seed sites are, their role in the effectiveness and impact of links, and why they matter.
Keep reading to learn more about how you can use this concept in delivering digital PR campaigns that have a real impact on your SEO success.
tl;dr You want links to your site from seed sites, and digital PR is a great way to earn these.
What Are Seed Sites & Link Distance Ranking?
Google’s “Producing a ranking for pages using distances in a web-link graph” patent makes reference to a set of seed pages and a ranking score that is generated for each page within a set based on the distance of these from the seed pages.
This is known as link distance ranking, and the score calculated is based on the distance between a set of seed sites and the pages to be ranked. The shorter the distance between the seed sites and a webpage, the higher the score.
Distance means how many links away a webpage is. You may think of this like click depth from outbound links.
Here’s the illustration that forms part of the patent:
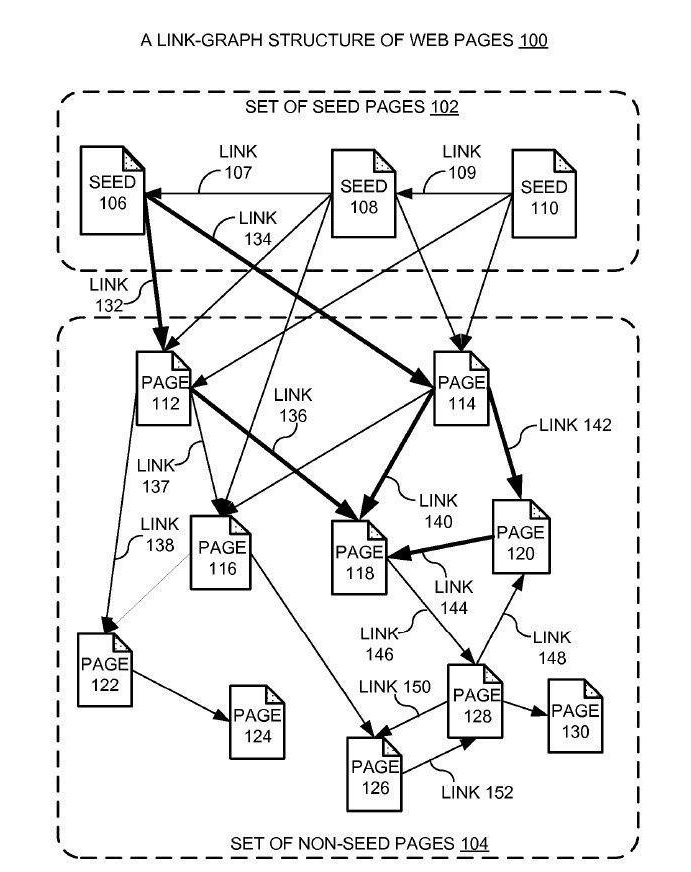
The patent’s abstract reads:
Methods, systems, and apparatus, including computer programs encoded on a computer storage medium, for producing a ranking for pages on the web.
In one aspect, a system receives a set of pages to be ranked, wherein the set of pages are interconnected with links. The system also receives a set of seed pages which include outgoing links to the set of pages.
The system then assigns lengths to the links based on properties of the links and properties of the pages attached to the links. The system next computes shortest distances from the set of seed pages to each page in the set of pages based on the lengths of the links between the pages.
Next, the system determines a ranking score for each page in the set of pages based on the computed shortest distances. The system then produces a ranking for the set of pages based on the ranking scores for the set of pages.
In everyday terms, what this means is that if your site is linked to from one or more sites from within a set of trusted sites (the seed set), you are, in theory, also deemed to be trusted. The further away you are from a seed site, the less trusted you are.
It is important to note, however, that the patent does not directly reference passing any form of ‘trust.’ It simply states that the algorithm “…discovers other pages which are likely to be good by following the links from the trusted pages.”
Think about it this way:
Site A (a seed site) links to site B which then links to site C, which then links to site D.
Site X (a seed site) links to site Y.
In this example, sites B and Y are linked to directly from a seed site. Whereas sites C and D aren’t. Site C sits a shorter distance from a seed site than site D, implying that sites B and Y are more trusted than C, which itself is more trusted than D.
The Similarities to TrustRank
The patent references Yahoo’s ‘Combating Web Spam with TrustRank‘, and there are a number of insights that we can take from this and discuss alongside Google’s link distance ranking system.
And it’s the abstract of the patent that introduces us to seed sites:
We first select a small set of seed pages to be evaluated by an expert. Once we manually identify the reputable seed pages, we use the link structure of the web to discover other pages that are likely to be good.
It goes on to confirm that this method can significantly filter out web spam with a set of seed sites smaller than 200 sites.
And one key point to raise from the TrustRank patent is the notion that ‘good’ pages rarely link to ‘bad’ pages. In the context of this, ‘bad’ pages refer to web spam.
Bad pages are built to mislead search engines, not to provide useful information. Therefore, people creating good pages have little reason to point to bad pages.
Whilst this is a simplified explanation of how sites link out to others, the patent goes on to explain that good pages can sometimes be tricked into linking to bad pages, as well as confirming that the reverse of this does not hold in the same way and that ‘bad’ pages often link to ‘good’ pages.
The purpose of seed sites, therefore, is to help an algorithm determine whether a particular webpage is ‘good’ or ‘bad,’ but prior to this, the seed set must be manually analysed by a human, and each site classified.
Following this, “the algorithm identifies other pages that are likely to be good based on their connectivity with the good seed pages.”
The further the distance between a seed page and the web page being classified, the lower the confidence that it is a ‘good’ page.
TrustRank suggests that the trust of a web page is reduced as the distance from ‘good’ seed pages increases.
And it’s this that we need to consider as we continue to look at the similarities with Google’s link distance ranking patent.
What we come back to here is the understanding that seed sites are considered trusted, most likely the most trusted. And based on the concept that ‘good’ sites rarely link to ‘bad’ sites, it makes sense that earning links from either seed sites, or those that sit only a short distance away from these, is something that we need to focus on.
But, this isn’t all.
We must also look to the 2006 “Topical TrustRank: using topicality to combat web spam” patent, which is referenced within the “Producing a ranking for pages using distances in a web-link graph” one.
This patent’s abstract states:
We propose the use of topical information to partition the seed set and calculate trust scores for each topic separately.
Why was this such an important development on the original TrustRank concept? Because this one addresses the major issue that the original faced, that it had a bias towards larger sites (communities), by calculating the trust scores on a per-topic basis.
What we must remember, however, is that these algorithms are intended to determine authority sites in multiple niches and across the web in general.
The “Producing a ranking for pages using distances in a web-link graph” algorithm is not a trust algorithm, as there is no “Trust” being passed by links.
This is important to understand, as this is where the similarities between TrustRank, Topical TrustRank and the main patent that we have been discussing end.
This is a link-distance algorithm, and there is nothing to suggest that “trust’ is being passed in the same way as PageRank is. Not at all.
All we know is that Google is measuring link distances from a trusted set of seed sites. This does not mean that ‘trust’ is being passed.
Further Insights from the ‘Scalable System for Determining Short Paths within Web Link Network’ Patent
If we turn our attention to another Google patent that has the same inventor as the “Producing a ranking for pages using distances in a web-link graph” one, we can gain further insights as to how seed sites are likely broken down into topical groupings.
The abstract for the ‘Scalable system for determining short paths within web link network‘ patent reads:
Systems and methods for finding multiple shortest paths.
A directed graph representing web resources and links are divided into shards, each shard comprising a portion of the graph representing multiple web resources.
Each of the shards is assigned to a server, and a distance table is calculated in parallel for each of the web resources in each shard using a nearest seed computation in the server to which the shard was assigned.
Reading deeper into the patent, we find references to “A large weighted digraph and a set of seed nodes (which may include hundreds of seeds) on a graph.”
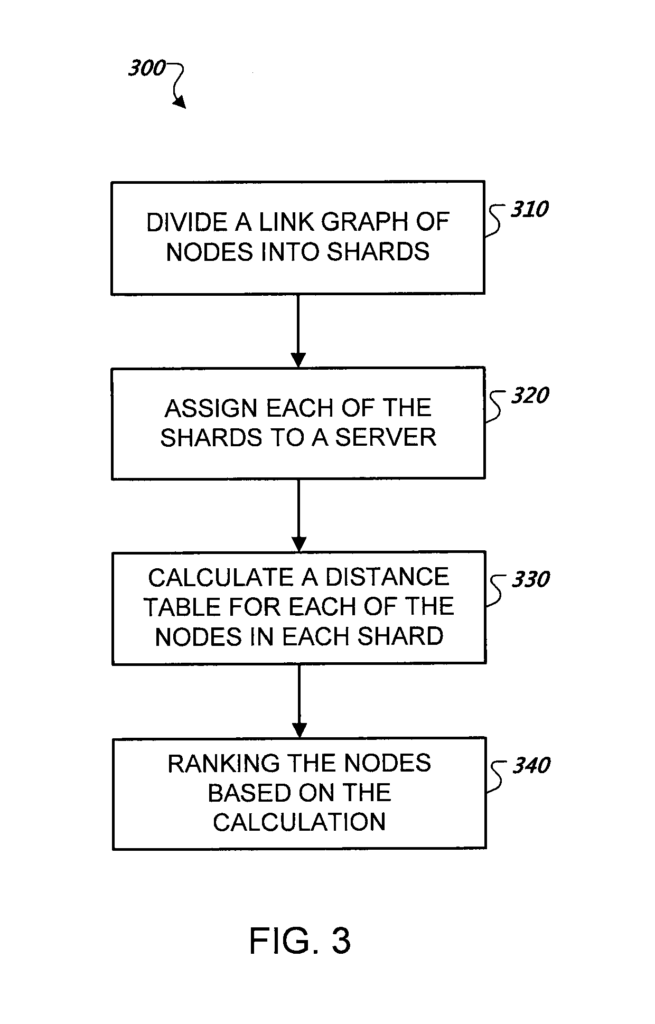
In other words, this set is broken down into shards, and the link distance is calculated within each of these.
We can assume that these shards are topics or niches.
And by diving deep into multiple patents that are related to one another, we can start to build up an understanding of the importance of the distance between potential seed sites and our own sites and build out link building and digital PR strategies around earning links from these.
An Active Patent Doesn’t Mean It’s Being Used
We must also address the fact that an active patent isn’t confirmed as one that’s used within Google’s algorithms.
Whilst a patent doesn’t necessarily mean that this is part of Google’s current ranking systems, “Producing a ranking for pages using distances in a web-link graph” was first granted in 2006 and updated in 2017. This one remains active through 2027 and is thought to be an update to the original PageRank patent.
Ultimately, by understanding the concept that links that are closer to a ‘trusted site’ (seed site), we can consider that these are deemed to be more valuable than those further away.
What we don’t get from the patents that reference seed sites is a black-and-white list of which sites these are, or even types of sites these are, to allow us to define which we need to earn links from. That’s not how this works, nor should it be. But what this does is help us to think carefully about the types of sites that align with the factors Google is selecting seed sites using.
It makes complete sense that sites being linked to by either other sites in the trusted seed set, or those close to this, are deemed more trustworthy, even if ‘trust’ is not a thing which is passed via links.
The Most Important Things You Need to Know About Seed Sites & Link Distance Ranking
The patents that reference seed sites are detailed and scientific, and reading these without a background understanding of computer science can make it difficult to take away much from them.
So here are the most important things you need to know about seed sites and link distance ranking, as found in the patents mentioned above.
- Each topic (niche/industry) has its own set of trusted seed sites. We don’t know what these are but know that The New York Times is an example that has been given by Google.
- The set of seed sites in the medical niche is different to the set of seed sites in the sports niche, for example.
- This allows sites in smaller and more obscure niches to become trusted, by earning links from their industry’s seed sites. Otherwise, this would make it difficult for smaller sites and niches to inherit PageRank.
- The closer a site is to one or more of these seed sites, the more trusted it is. Closer means the fewest links away from these sites.
- You want to earn links from sites that are likely seed sites or those close to these.
- Think about ‘authoritative sites’ as those within your own industry, not just those with a high DA or large presence.
- This should, in itself, define your stance towards the relevancy of links earned, pushing you to focus on identifying and earning links from your own industry’s most authoritative sites.
What Does this Mean for Digital PRs?
We know that links continue to be a major SEO ranking factor, despite recent confirmation from Google that they’re no longer in the top three.
But what does the understanding of seed sites and link distance ranking mean for digital PRs and the way you should run activity?
The honest answer, for most, is that this just confirms the importance of the tactic and that relevance of the links earned should be the primary KPI and measure of success.
But for those still not convinced that niche relevant links can contribute to SEO success? This goes a long way to confirming the importance of these.
You need to focus, first and foremost, on links that position you as an authority in your niche.
By prioritising earning links from those sites that are considered to be the most authoritative in your industry, you’re doing everything within your control to earn links from those the closest as possible to the seed site set.
Possible Seed Site Examples
Whilst we only have The New York Times and Google Directory (RIP) confirmed by Google as examples of sites in the seed set, what we do know is that this contains sites that are:
- Reliable
- High-quality pages
- Well-connected to other non-seed pages (lots of outbound links)
Of course, we also know these are broken into topics, confirmed by the reference that these sites are “diverse to cover a wide range of fields of public interests.”
So let’s make some assumptions about what sites could either be considered seed sites or ones that sit very close to these?
And let’s remember that we don’t actually need to know the specific sites in the seed set. There’s a strong likelihood that this changes over time (the web doesn’t stand still, it’s got to, really…), but getting into the mindset of earning links from these types of sites, by default, puts you in a strong position to be considered a trusted site.
Here’s what I believe could be considered seed set sites (or authority sites) in 3 different industries:
| Industry | Site |
|---|---|
| Travel | Lonely Planet |
| Travel | Travel & Leisure |
| Travel | Conde Nast Traveller |
| Travel | AFAR |
| Finance | The Wall Street Journal |
| Finance | Fortune |
| Finance | The Economist |
| Finance | Financial Times |
| Sports | ESPN |
| Sports | The Sporting News |
| Sports | Bleacher Report |
| Sports | CBS Sports |
So is a link from Lonely Planet a more valuable link for a travel brand than one from Financial Times? You bet…
Spend time identifying the most authoritative and trusted sites in your industry and put together a digital PR strategy that targets these as your priority.
Of course, this isn’t to say that other links aren’t valuable. They are, and we must remember that these patents do not suggest that Trust is passed by links, just that these sites are deemed to be trusted the closer they are to a seed site.
Digital PR: Your Biggest Opportunity to Earn Links from Seed Sites
The very nature of digital PR presents a significant opportunity for you to earn links from sites that are likely either in, or close to, a trusted seed set of sites.
Whilst we don’t know, and will likely never know, what the seed sites in each niche are, what we do know is that these are the most trusted and authoritative ones.
And the fact that these align very nicely with the types of sites that digital PR allows you to earn links from keeps it the #1 tactic for earning links, as well as demonstrating E-E-A-T in the wider sense, as far as I’m concerned.
You might also be interested in our guide to the role of digital PR in demonstrating E-E-A-T.